Knowledge base pro AI: Jak připravit firemní data
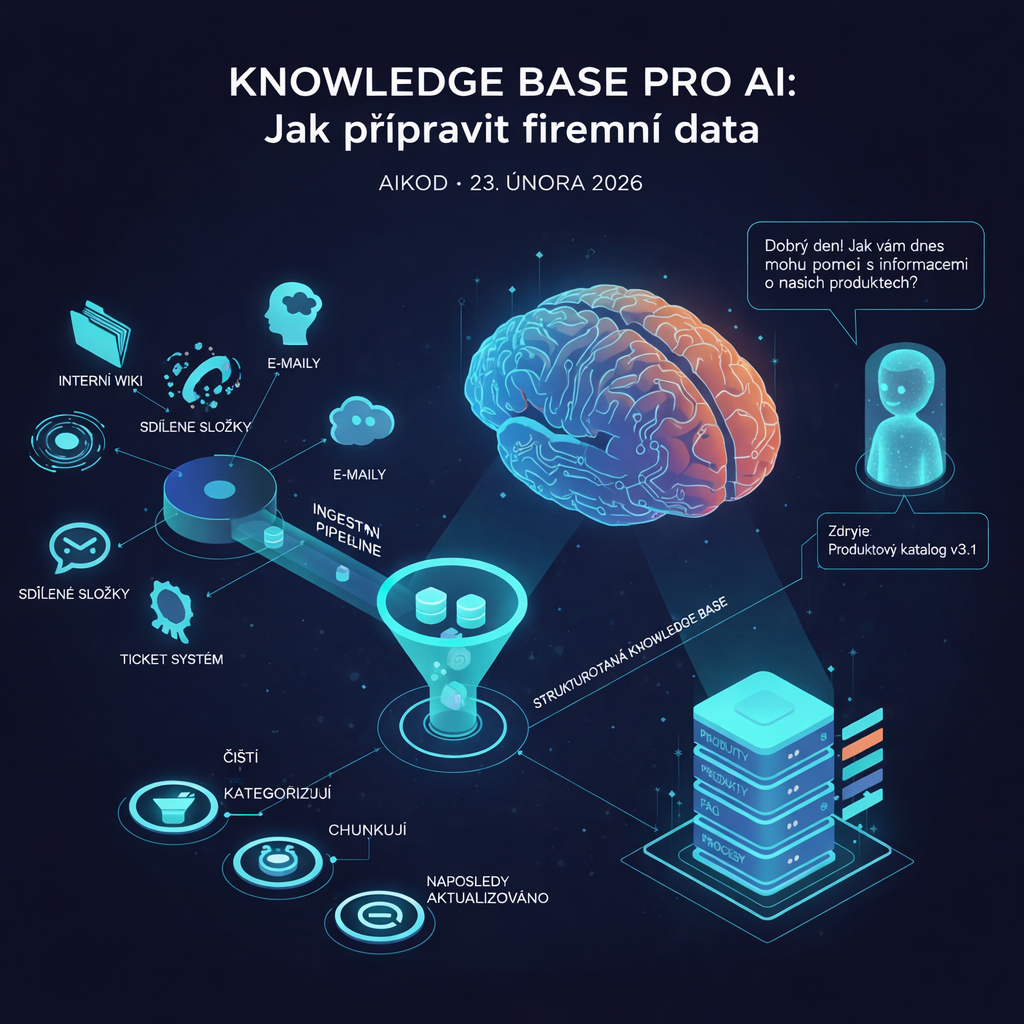
Většina firem má znalosti roztroušené v desítkách systémů: interní wiki, sdílené složky, e-maily, ticketovací systém, hlavy zaměstnanců. Když chcete nasadit AI chatbota nebo interního asistenta, první otázka zní: kde vezmeme data? Odpověď je jednoduchá, ale provedení náročné — musíte vytvořit strukturovanou knowledge base, kterou AI dokáže efektivně využít.
Příprava knowledge base je často podceňovanou fází AI projektů. Týmy se soustředí na výběr modelu a technickou implementaci, zatímco kvalita podkladových dat rozhoduje o úspěchu nebo selhání celého řešení. AI je jen tak dobrá, jak dobré jsou informace, ze kterých čerpá.
V tomto článku projdeme celý proces přípravy firemní knowledge base pro AI: od auditu existujících zdrojů přes čištění a strukturování až po údržbu a aktualizace. Získáte praktický framework, který můžete aplikovat bez ohledu na velikost firmy nebo odvětví.
Obsah
Proč je knowledge base klíčová pro AI
AI chatboty a asistenti fungují na principu RAG (Retrieval-Augmented Generation) — když dostanou dotaz, nejprve vyhledají relevantní informace v knowledge base a teprve pak generují odpověď. Kvalita knowledge base přímo určuje, zda chatbot odpoví správně, nebo bude halucinovat.
Bez kvalitní knowledge base čelíte několika problémům. AI nemá přístup k firemně specifickým informacím — nezná vaše produkty, procesy, cenovou politiku. Obecný model jako GPT-4 ví hodně o světě, ale nic o vaší firmě. Odpovědi budou generické nebo chybné.
S nekvalitní knowledge base je situace někdy ještě horší. AI najde relevantní dokument, ale informace v něm je zastaralá, neúplná nebo nekonzistentní. Chatbot pak s jistotou prezentuje nesprávné informace, protože je "našel ve zdrojích". Zákazník dostane špatnou odpověď s falešným pocitem důvěryhodnosti.
Kvalitní knowledge base přináší měřitelné výsledky. E-shop s dobře připravenou produktovou dokumentací redukuje dotazy na support o 40-60 %. Interní asistent s přístupem ke strukturovaným procesům zkracuje onboarding nových zaměstnanců o týdny. B2B firma s kompletní technickou dokumentací zvyšuje spokojenost zákazníků s technickou podporou.
Investice do knowledge base se navíc zúročí vícekrát. Stejná dokumentace slouží AI chatbotovi, internímu vyhledávání, onboardingu zaměstnanců i jako podklad pro marketing. Jednou vytvořený strukturovaný obsah má multiplikační efekt.
Audit existujících znalostních zdrojů
Prvním krokem je zmapování všech míst, kde firma ukládá znalosti. Obvykle jich je mnohem více, než si vedení uvědomuje. Systematický audit odhalí jak cenné zdroje, tak problematické mezery.
Interní dokumentace zahrnuje wiki systémy (Confluence, Notion, interní řešení), sdílené složky (Google Drive, SharePoint, lokální servery), procesní dokumentaci a pracovní postupy. Tyto zdroje jsou typicky nejhodnotnější, ale také nejméně strukturované.
Zákaznická dokumentace obsahuje FAQ, help centrum, produktové manuály, návody a tutoriály. Tento obsah je obvykle lépe strukturovaný, protože byl vytvořen pro externí konzumenty. Problémem může být neaktuálnost u starších produktů.
Komunikační archivy skrývají implicitní znalosti: e-mailové vlákna s řešením specifických problémů, ticketovací systém s historií support interakcí, Slack/Teams konverzace s technickými diskusemi. Extrakce těchto znalostí je náročná, ale cenná.
Expertní znalosti existují pouze v hlavách zaměstnanců. Senior technici vědí, jak řešit edge cases, které nikdo nezadokumentoval. Obchodníci znají neformální dohody s klíčovými klienty. Tyto znalosti je nutné aktivně zachytit formou interview nebo shadowing.
Strukturovaná data v databázích a systémech (ERP, CRM, produktový katalog) poskytují přesné informace, ale vyžadují transformaci do formátu čitelného pro AI. Propojení s live systémy umožňuje real-time odpovědi.
Výstupem auditu by měl být inventář zdrojů s hodnocením kvality, aktuálnosti a priority pro zahrnutí do knowledge base. Ne všechny zdroje stojí za zpracování — fokus na high-impact obsah přináší rychlejší ROI.
Strukturování a formátování obsahu
Surová dokumentace z auditu většinou není přímo použitelná pro AI. Potřebuje strukturování, které usnadní vyhledávání relevantních částí a poskytne dostatečný kontext pro generování odpovědí.
Hierarchická struktura organizuje obsah od obecného ke specifickému. Top-level kategorie odpovídají hlavním tématům (produkty, procesy, politiky). Sub-kategorie zpřesňují (Produkt A > Technické specifikace > Rozměry). Tato hierarchie pomáhá AI pochopit vztahy mezi informacemi.
Atomické dokumenty obsahují jednu ucelenou znalost. Místo jednoho 50stránkového manuálu vytvořte desítky menších dokumentů, každý zaměřený na specifické téma. AI pak může přesně vyhledat relevantní část místo procházení celého dokumentu.
Konzistentní formátování usnadňuje strojové zpracování. Definujte šablony pro různé typy obsahu: produktový list, procesní postup, FAQ položka, troubleshooting guide. Každá šablona má pevnou strukturu sekcí, které AI očekává.
Explicitní kontext eliminuje ambiguity. Dokument by měl obsahovat informace nutné pro pochopení bez znalosti kontextu: pro který produkt/verzi platí, kdy byl naposledy aktualizován, kdo je autorita pro danou oblast. AI pak může správně interpretovat i vytržené pasáže.
Příklad strukturované FAQ položky:
Téma: Vrácení zboží
Produkt: Všechny produkty
Platnost: Od 1.1.2026
Poslední aktualizace: 15.2.2026
Otázka: Jaká je lhůta pro vrácení zboží?
Odpověď: Spotřebitel může vrátit zboží bez udání důvodu do 14 dnů od převzetí. Firemní zákazníci (B2B) nemají zákonný nárok na vrácení, ale nabízíme 7denní lhůtu jako benefit.
Postup vrácení:
1. Vyplňte formulář na [odkaz]
2. Zabalte zboží v původním obalu
3. Odešlete na adresu skladu
4. Refund obdržíte do 14 dnů od doručení
Související: Reklamace, Výměna zboží, Doprava
Čištění a deduplikace dat
Raw dokumentace obsahuje množství problémů, které degradují kvalitu AI odpovědí. Systematické čištění je časově náročné, ale nezbytné pro spolehlivý výsledek.
Duplicity vznikají, když stejná informace existuje na více místech v různých verzích. Zákazník se ptá na ceník a AI najde tři různé dokumenty s třemi různými cenami. Identifikujte kanonický zdroj pro každý typ informace a odstraňte nebo označte duplikáty.
Zastaralý obsah je nebezpečnější než chybějící obsah. Stará dokumentace k produktu, který už nevypadá stejně. Procesní postupy, které firma opustila před roky. Kontaktní údaje bývalých zaměstnanců. Proveďte review s vlastníky obsahu a archivujte nebo smažte neaktuální materiály.
Nekonzistence v terminologii mate AI i uživatele. Jeden dokument říká "zákazník", druhý "klient", třetí "uživatel" — znamenají totéž, nebo jsou to různé segmenty? Vytvořte slovník firemní terminologie a sjednoťte používání klíčových termínů.
Neúplné informace vedou k částečným nebo chybným odpovědím. Procesní postup, který popisuje kroky 1-5, ale chybí krok 6. Produktový list bez ceny. FAQ bez odpovědi. Identifikujte mezery a doplňte chybějící informace.
Formátovací problémy komplikují strojové zpracování. Tabulky vložené jako obrázky. Text v PDF, který nelze extrahovat. Word dokumenty s rozbitým formátováním. Převeďte obsah do čistých textových formátů (Markdown, plain text) se zachováním struktury.
Pro efektivní čištění vytvořte checklist kritérií kvality a projděte každý dokument. Zapojte vlastníky obsahu pro validaci factual accuracy. Automatizujte, co lze automatizovat (detekce duplicit, broken links), ale ruční review je nezbytný.
Kategorizace a metadata
Metadata transformují hromadu dokumentů v prohledatelnou knowledge base. Správná kategorizace umožňuje AI filtrovat výsledky podle kontextu dotazu a poskytovat relevantnější odpovědi.
Taxonomie kategorií definuje hlavní dimenze, podle kterých obsah třídíte. Typické dimenze pro firemní knowledge base:
Produkt/služba (ke kterému produktu se informace vztahuje)
Typ obsahu (FAQ, manuál, proces, politika)
Audience (zákazník, zaměstnanec, partner)
Životní cyklus (pre-sales, onboarding, support, renewal)
Povinná metadata by měl mít každý dokument:
Jedinečný identifikátor
Název/titulek
Kategorie podle taxonomie
Datum vytvoření a poslední aktualizace
Autor/vlastník
Status (draft, published, archived)
Volitelná metadata obohacují kontext:
Klíčová slova/tagy
Související dokumenty
Verze produktu
Geografická platnost
Úroveň důvěrnosti
Automatická vs manuální kategorizace: Pro velké knowledge base je manuální tagování všech dokumentů nerealistické. Využijte AI pro automatickou kategorizaci — LLM dokáže přiřadit dokumenty do kategorií na základě obsahu. Manuální review pak stačí pro edge cases a validaci.
Příklad metadat v YAML frontmatter:
---
id: kb-return-policy-001
title: Vrácení zboží do 14 dnů
category: policies
product: all
audience: customer
lifecycle: support
created: 2025-06-01
updated: 2026-02-15
author: customer-support-team
status: published
tags: [vrácení, refund, 14 dnů, spotřebitel]
related: [kb-exchange-policy, kb-complaint-process]
---
Technické formáty pro AI systémy
Volba technického formátu ovlivňuje, jak efektivně AI systém dokáže knowledge base zpracovat a využít. Různé formáty mají různé trade-offs mezi srozumitelností, strukturou a kompatibilitou.
Markdown je ideální volbou pro většinu firemního obsahu. Je lidsky čitelný, snadno se edituje, podporuje strukturování (nadpisy, seznamy, tabulky) a většina AI systémů ho dobře zpracovává. YAML frontmatter umožňuje přidání metadat. Verzování v Git poskytuje historii změn.
JSON/JSONL je vhodný pro strukturovaná data s konzistentním schématem: produktové katalogy, FAQ databáze, konfigurace. Strojově zpracovatelný, ale méně čitelný pro lidi. Validace pomocí JSON Schema zajišťuje konzistenci.
Plain text je nejjednodušší formát bez formátování. Vhodný pro krátké snippety, definice, jednotlivé odpovědi. Minimální overhead, maximální kompatibilita.
PDF je problematický formát. Extrakce textu z PDF je nespolehlivá, zejména u skenovaných dokumentů nebo komplexních layoutů. Pokud máte důležitý obsah v PDF, převeďte ho do Markdown nebo plain textu.
HTML z webových stránek vyžaduje čištění od navigace, reklam a boilerplate. Nástroje jako Trafilatura nebo Readability extrahují hlavní obsah. Zachovávejte sémantickou strukturu (nadpisy, seznamy).
Chunking strategie určuje, jak jsou dokumenty rozděleny pro indexování. Typická velikost chunku je 200-500 tokenů. Respektujte přirozené hranice (odstavce, sekce). Překryv mezi chunky (50-100 tokenů) zachovává kontext na hranicích.
Pro produkční nasazení doporučujeme standardizovat na Markdown s YAML frontmatter pro dokumentaci a JSON pro strukturovaná data. Automatizujte konverzi z ostatních formátů jako součást ingestion pipeline.
Procesy údržby a aktualizace
Knowledge base není jednorázový projekt, ale živý organismus vyžadující kontinuální péči. Bez procesů údržby kvalita rychle degraduje a AI začne poskytovat zastaralé nebo nesprávné informace.
Ownership model definuje, kdo je zodpovědný za který obsah. Každý dokument nebo sekce by měla mít přiřazeného vlastníka, který zajišťuje aktuálnost. Vlastnictví by mělo být součástí job description, ne dobrovolná aktivita.
Review cyklus stanovuje frekvenci kontrol. Kritický obsah (ceny, právní informace, procesy) review kvartálně. Stabilní dokumentace (produktové specifikace, technické manuály) review ročně. Automatické připomínky vlastníkům před plánovaným review.
Trigger-based aktualizace reagují na události vyžadující změnu. Nový produkt? Vytvořte dokumentaci. Změna procesu? Aktualizujte návody. Reklamace kvůli nesprávné informaci? Okamžitá oprava. Integrace s ostatními systémy (PIM, CRM, helpdesk) automatizuje detekci triggerů.
Feedback loop z AI chatbota identifikuje mezery. Analyzujte dotazy, na které chatbot nedokázal odpovědět nebo odpověděl špatně. Eskalace na lidskou podporu signalizují chybějící dokumentaci. Uživatelské hodnocení odpovědí odhaluje problémy kvality.
Verzování a audit trail umožňují sledovat změny a případně se vrátit k předchozí verzi. Git pro Markdown dokumenty. Changelog pro významné změny. Audit log pro compliance-sensitive obsah.
Governance struktura pro větší organizace zahrnuje:
Content owners: odborníci zodpovědní za specifické oblasti
Content editors: udržují konzistenci a kvalitu
Knowledge manager: orchestruje procesy, reportuje metriky
Steering committee: rozhoduje o prioritách a zdrojích
Časté chyby a jak se jim vyhnout
Implementace knowledge base pro AI skrývá několik pastí, které vedou k neúspěchu projektu nebo suboptimálním výsledkům. Znalost těchto chyb vám ušetří čas a frustraci.
"Nasypeme tam všechno" je první impuls, kterému je třeba odolat. Více dat neznamená lepší AI. Nekvalitní, zastaralá nebo irelevantní dokumentace zhoršuje výsledky. Selektivní kurátorství přináší lepší výsledky než kvantita. Začněte s high-impact obsahem a postupně rozšiřujte.
Jednorázový projekt bez plánu údržby je recept na degradaci. Tři měsíce po launchi je polovina obsahu zastaralá. Zabudujte procesy údržby od začátku, ne jako afterthought. Budget na ongoing maintenance, ne jen initial development.
Ignorování expertních znalostí v hlavách zaměstnanců vytváří mezery. Dokumentace zachycuje formální procesy, ale tipy, triky a workaroundy senior zaměstnanců ne. Aktivně extrahujte tacit knowledge formou interview, shadowing nebo pair documentation.
Over-engineering struktury na začátku vede k paralýze. Perfektní taxonomie neexistuje a požadavky se budou měnit. Začněte s jednoduchou strukturou a iterujte na základě reálného použití. Refaktoring je normální součást procesu.
Nedostatek validace s uživateli ignoruje skutečné potřeby. Dokumentace odpovídá na otázky, které si myslíte, že lidé mají, ne na ty, které skutečně mají. Analyzujte reálné dotazy z helpdesku, vyhledávání, chatbota. Validujte strukturu s reprezentativními uživateli.
Podceňování náročnosti vede k podcenění zdrojů a timeline. Příprava kvalitní knowledge base zabere měsíce, ne týdny. Zahrňte do plánu čas na audit, čištění, strukturování, review a iterace. Realistická očekávání předejdou frustraci.
FAQ
Jak velká by měla být knowledge base pro AI chatbota?
Velikost závisí na komplexitě vašeho byznysu. Typický e-shop potřebuje 100-500 dokumentů pokrývajících produkty, procesy a FAQ. B2B firma s komplexními produkty může mít 1000+ dokumentů. Důležitější než velikost je pokrytí — AI by měla mít odpověď na 80%+ běžných dotazů.
Jak často aktualizovat knowledge base?
Kritický obsah (ceny, dostupnost, právní informace) aktualizujte real-time nebo denně. Procesní dokumentace při každé změně procesu. Stabilní obsah review ročně. Nastavte automatické remindery vlastníkům obsahu pro plánované review.
Můžu použít existující Confluence/Notion jako knowledge base?
Ano, většina RAG systémů má konektory pro populární wiki platformy. Ale samotné propojení nestačí — stále potřebujete audit, čištění a strukturování obsahu. Confluence plné zastaralých stránek vytvoří zastaralého chatbota.
Jak řešit důvěrné informace v knowledge base?
Implementujte access control na úrovni dokumentů nebo sekcí. Tagujte obsah podle úrovně důvěrnosti. AI chatbot by měl kontrolovat oprávnění uživatele před zahrnutím citlivých dokumentů do kontextu. Pro veřejné chatboty vytvořte separátní "public" knowledge base.
Kdo by měl být zodpovědný za knowledge base?
Ideálně dedikovaný Knowledge Manager nebo Content Operations role. V menších firmách může být zodpovědnost součástí jiné role (Product Owner, Customer Success). Klíčové je jasné ownership a alokovaný čas — knowledge base jako "side project" nefunguje.
Potřebujete pomoc s přípravou knowledge base pro AI chatbota? Kontaktujte nás pro konzultaci a návrh implementace.